19/08/2017
ΤΕΧΝΟΛΟΓΙΑ: Αυτοματοποιημένη δημοσιογραφία και το πρόβλημα των δεδομένων
Nick Hagar
Dallas Morning News intern, Medill Σχολή Δημοσιογραφίας
Νωρίτερα αυτή την εβδομάδα, το κέντρο κατασκόπων του Πανεπιστημίου της Κολούμπια δημοσίευσε μια έκθεση σχετικά με την προσπάθειά της να αυτοματοποιήσει ειδησεογραφικά άρθρα σχετικά με τις προεδρικές εκλογές, ένα έργο που δημιούργησε σχεδόν 22.000 κομμάτια κατά τις εκλογές του 2016. Μπορείτε να διαβάσετε το όλο θέμα εδώ . Θέλω να επικεντρωθώ στα προβλήματα που αντιμετώπισε αυτό το πρόγραμμα, ένα κύριο θέμα της έκθεσης:
Η προσθήκη πρόσθετων στοιχείων γρήγορα αυξάνει την πολυπλοκότητα σε ένα επίπεδο που είναι δύσκολο να διαχειριστεί. Λόγω της πλήρως αυτοματοποιημένης διαδικασίας, ο ρυθμός σφαλμάτων στα τελικά κείμενα ήταν υψηλός. Τα περισσότερα σφάλματα προέκυψαν εξαιτίας σφαλμάτων στα δεδομένα προέλευσης. ... Είναι δύσκολο να αναπτυχθεί ένας αλγόριθμος "one-fit-all" για διαφορετικούς τύπους ιστοριών. Η συμφραζόμενη γνώση είναι ένα όριο αυτοματοποίησης που επιτυγχάνεται γρήγορα.
Οι ερευνητές βάζουν την ευθύνη για τους περιορισμούς του έργου τους στα όρια της τεχνολογίας, μια εξήγηση που δεν ταιριάζει με άλλες συναρπαστικές εργασίες επεξεργασίας φυσικής γλώσσας. Η επιλογή εφαρμογής τους μπορεί να ήταν το θέμα, όπως δείχνει το παράδειγμα αυτό:
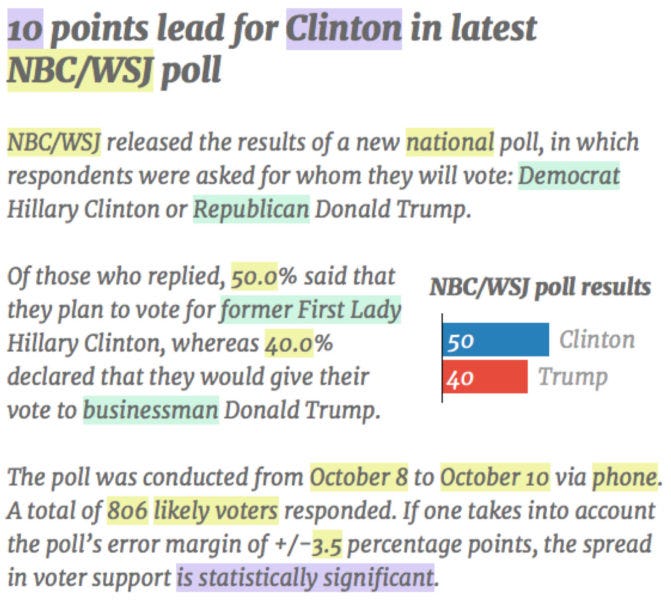
Εικόνα από την αναφορά
Η κίτρινη επισήμανση εμφανίζει δεδομένα που απλώς λαμβάνονται από τα ανεπεξέργαστα δεδομένα και εισάγονται στο κείμενο: το όνομα της δημοσκόπησης, οι πραγματικοί αριθμοί τηλεφώνου του υποψηφίου ή άλλα στατιστικά στοιχεία όπως η περίοδος δημοσκοπήσεων, το μέγεθος δείγματος ή το περιθώριο σφάλματος ... Η μωβ επισημάνετε τα πεδία που βασίζονται σε υπολογισμούς με τα ακατέργαστα δεδομένα. Για παράδειγμα, ο αλγόριθμος προέρχεται από τα στοιχεία που (α) η Κλίντον είναι μπροστά στη δημοσκόπηση, (β) είναι μπροστά από 10 πόντους και αυτό το προβάδισμα είναι στατιστικά σημαντικό. Έτσι, ο αλγόριθμος βασίζεται σε ένα σύνολο προκαθορισμένων κανόνων. ... Τα πράσινα πεδία επισημαίνουν συνώνυμα δείγματος, τα οποία χρησιμοποιούνται για την προσθήκη ποικιλίας στο κείμενο.
Φαίνεται ότι πολλές χειρωνακτικές εργασίες πήγαν στην προετοιμασία αυτού του αλγορίθμου. Αν οι ερευνητές βρήκαν με το χέρι λίστες λέξεων και φράσεων για να χρησιμοποιήσουν το πρόγραμμα, τότε φυσικά δεν θα ήταν σε θέση να χειριστούν άγνωστες περιπτώσεις. Αυτό δεν είναι αυτοματοποίηση στην αίσθηση της μηχανής μάθησης. Μάλλον, είναι ένα πολύ συγγραφικό υπόδειγμα με κάποια λογική που έχει ψηθεί για να χειριστεί δυναμικές τιμές, πράγμα που φυσικά οδηγεί σε αυτό το πρόβλημα:
Φτάσαμε στα όρια του αυτοματισμού ταχύτερα από το αναμενόμενο. Κατά την ανάπτυξη των υποκείμενων κανόνων του αλγορίθμου, αντιμετωπίζουμε συνεχώς ερωτήματα, όπως: Πώς πρέπει να αναφερθούμε στο περιθώριο μεταξύ των υποψηφίων στις δημοσκοπήσεις; Πότε ένας υποψήφιος έχει μια δυναμική; Πότε υπάρχει μια τάση στα δεδομένα; Παρόλο που τέτοιου είδους ερωτήσεις μπορεί να είναι εύκολο να απαντηθούν για έναν ανθρώπινο δημοσιογράφο, είναι δύσκολο να λειτουργήσουν και να τεθούν σε προκαθορισμένους κανόνες.
Ο ισχυρισμός ότι έχει «φτάσει στα όρια της αυτοματοποίησης» με μια προσέγγιση σε ένα πείραμα υπονομεύει τις τεχνικές δυνατότητες που δεν εξετάζονται εδώ. Ναι, υπάρχουν όρια σε μια προσέγγιση συμπληρώματος-κενών προτύπων, αλλά είναι εγγενή στη μορφή. Το πιο εντυπωσιακό για μένα είναι ένα βασικό πρόβλημα με τους μηχανισμούς που επικαλείται το έργο αυτό:
Το PollyVote κατάργησε αυτόματα τα δεδομένα από μια ποικιλία ιστότοπων, μια διαδικασία που είναι επιρρεπής σε σφάλμα (π.χ. εάν ο ιστότοπος στόχος δεν ήταν διαθέσιμος ή η δομή των δεδομένων προέλευσης άλλαξε). Έτσι, ορισμένα κείμενα δεν θα δημιουργηθούν εξαιτίας φίλτρων για δεδομένα που λείπουν, ενώ άλλα θα δημιουργηθούν με σφάλματα μέχρι να διορθωθούν τα σφάλματα.
Η διδασκαλία ενός υπολογιστή για να γράψετε άρθρα είναι το δροσερό και συναρπαστικό μέρος αυτού του πεδίου, αλλά το βαρετό έργο της συλλογής δεδομένων και της δομής είναι αυτό που πραγματικά θα καταστήσει αυτό το μέλλον εφικτό. Τα ανοικτά, καθαρά, τακτικά ενημερωμένα δεδομένα δεν είναι αρκετά κοινά για να υποστηρίξουν μια αυτόματη λειτουργία ειδήσεων. Αυτό καθιστά την ανύψωση πληροφοριών από ιστότοπους με αποξεστήρες ιστού τη μόνη επιλογή, μια μη βιώσιμη προσέγγιση που εξαρτάται από ένα τεράστιο δίκτυο απρόβλεπτα μεταβαλλόμενων ιστότοπων.
Ο στόχος των αυτοματοποιημένων ειδήσεων δεν πρέπει να είναι μόνο να διδάσκουν στον υπολογιστή πώς να γράφουν. Θα πρέπει να εξαλείψει όσο το δυνατόν περισσότερο το μπαστούνι στο backend, ελευθερώνοντάς μας από το να κατασκευάζουμε περίπλοκα δελτία κανόνων και να διορθώνουμε τις ξύστρες. Υπάρχουν καλύτερες τεχνικές λύσεις για την παραγωγή ιστοριών από τα δυναμικά πρότυπα, εκείνα που θα έρθουν με περισσότερη έρευνα. Αλλά αυτές οι λύσεις εξαρτώνται από πολλά καλά δεδομένα, κάτι που πρέπει να επικεντρωθούμε στο να υπολογίσουμε πώς να φτάσουμε τώρα.
____________________________________________
«Τα κράτη της Μέσης Ιδρυτής :
Υπουργείο Εξωτερικών των ΗΠΑ
Παγκόσμιου Οργανισμού Πνευματικής Ιδιοκτησίας (IP)»
Πήγαινε στο προφίλ του Σπυρίδωνα Liar
Σπυρίδων Liar
Μέσης μέλος Απριλίου 2017